About Data Structures
Wikipedia says:
In computer science, a data structure is a particular way of organizing data in a computer so that it can be used efficiently.
That makes a good deal of sense, I think. The main point here is that data structures exist to store data efficiently. For example, an array of strings might not be the best way to store the URLs of every website Google has ever indexed. Arrays, JavaScript objects, associative arrays in PHP, and relational databases are pretty much the only data structures I can think of off the top of my head, so today, I am happy to add to the mix:
Day 1: Linked Lists
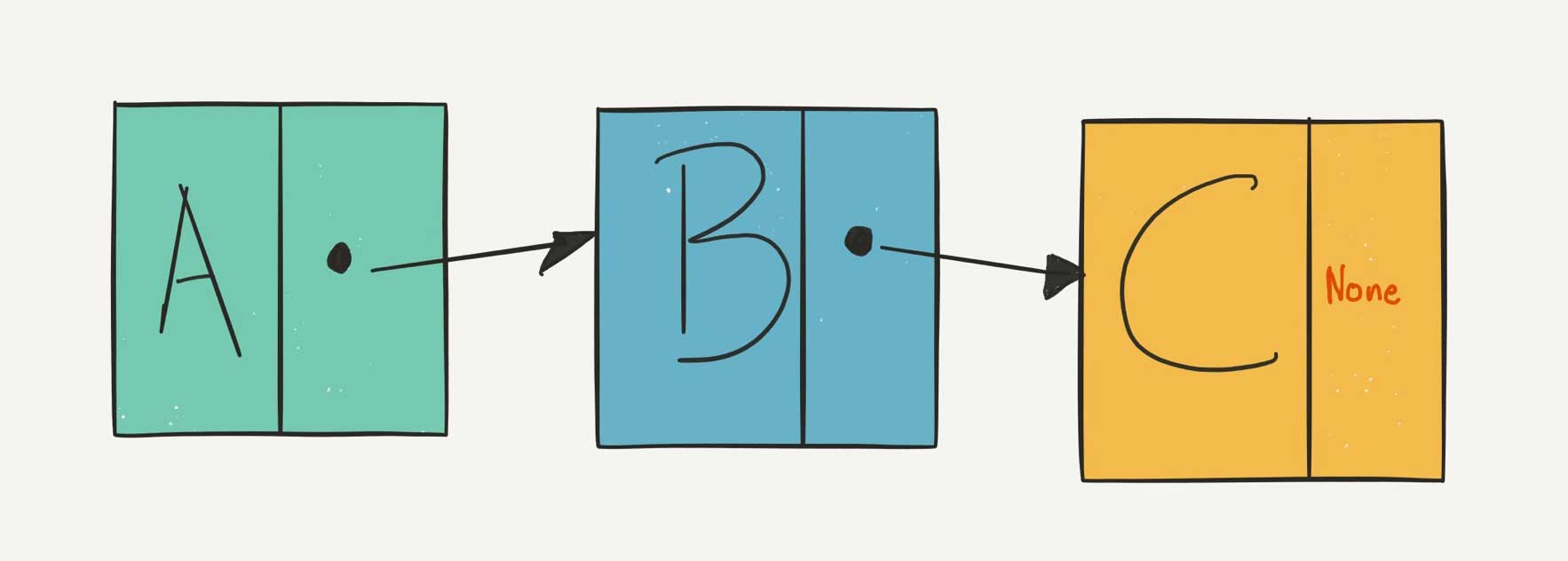
Linked lists are very similar to arrays in that they are a one-dimensional list of elements. Unlike arrays, however, in a linked list, you cannot just jump to index 4, you have to walk through the list, starting with the “head”, or the first element in the list, and work your way through to the fourth element. Here’s a very redimentary illustration:

There are also doubly linked lists: In addition to linking to the element following it, each element is connected to the element previous to it as well. In other words, you can move forward and backward between element rather than just forwards. So, in the above illustration, add an arrow that points back in addition to the forward pointing ones.
In the real world
The visualization of a linked list and the mention of a head reminds me of the way commits look in a Git branch, and according to this Quora post, linked lists are a big part of how Git works. The concept of the “head” in particular is exactly like the head in a linked list, while each commit represents a linked list node. Commits are always added to the top of a branch, just like new nodes are always added to the top of a linked list.

Another example (taken from this CodeTuts article by Cho Kim) is a scavenger hunt. There is a list of tasks in a scavenger hunt, but you have to start from the beginning; jumping to the third task in the hunt wouldn’t make sense if you hadn’t completed the first two.
When are they useful?
You can insert/delete an element at the beginning of a linked list, it can be done in constant time which, I think, means you don’t have the overhead processing time of first finding an element in an array. If you know the adding/removing of items will always be the first one, then a linked list is very helpful.
TBQH: That explanation doesn’t really mean much to me. Maybe I’ll flesh out this section at a later date.
Update: I was pointed to Vaidehi Joshi’s fantastic series on computer science fundamentals called “basecs”, and she describes linked lists and there uses very, very well. Check out part 1 and part 2, but in essencee here’s why they are useful:
Because a single node has the “address” or a reference to the next node, they don’t need to live right next to one another, the way that the elements have to in an array. Instead, we can just rely on the fact that we can traverse our list by leaning on the pointer references to the next node, which means that our machines don’t need to block off a single chunk of memory in order to represent our list.
Basically, instead of storing an actual node, you are storing references to nodes and they can live wherever in memory.
In JavaScript
Whereas JavaScript has a lot of built-in methods for handling arrays, there isn’t any data type for a linked list in JavaScript. We can’t just say var list = new LinkedList(); and have access to methods akin to push and pop, rather, we have to build out the idea of a “node” and corresponding methods for adding, removing, and selecting items within the linked list.
The CodeTuts article linked above is fantastic, and my strategy for learning this was to follow the tutorial and first write the code out by hand in a notebook (practicing for whiteboard time). Then I tried to rewrite the program myself in a text editor. I used plain ol’ JavaScript file, linked-list.js, and checked my results in the command line with node linked-list.js. My code is pretty much the same as the tutorial, but I used ES6 classes to define the objects and methods for the linked list rather than prototypical inheritance which is in the tutorial. It seemed to work quite nicely!
The biggest “aha” moment for me about the linked list was that you can’t just console.log(list) like you could with an array. The list itself is comprised of references to nodes, not the actual nodes like a standard JS object or array would be.
I will now explain the overall structure of the linked list piece by piece. The full code is in this Gist.
// Make an object-prototype-class-thing to handle the properties of a list node
class Node {
constructor(data) {
this.data = data;
this.next = null;
}
}Each node has properties for data, or a bit of text for identifying the node, as well as a next property. Since linked lists are based on relationships between nodes, each Node needs to contain a reference to the next node.
Next, we need to create an object-prototype-class-thing to handle the properties and methods of the linked list itself:
// Calling it SinglyList because you can also create "doubly lists" that have references to previous and next nodes. This is just a "singly list".
class SinglyList {
// Setting defaults for an empty list
constructor(length = 0, head = null) {
this._length = length;
this.head = head;
}
// See full gist for methods' contents - just indicating where they would go here.
add(value) { }
selectNodeAt(position) { }
remove(position) { }
}Like the node above, the list has a couple of key properties including its length and the location of the head. The “head” will be assigned to a “Node”, and the length will, of course, be an integer. The weird part about all of this is that there’s not actually a list anywhere – it’s all dependent on our manually incrementing the length and assigning nodes to this.head accordingly.
Finally, here’s the linked list in action:
// Create a new list! Yeah!
const list = new SinglyList();
list.add("hey");
list.add("ho");
list.add("hum");
list.add("bum");
list.remove(1); // Remove "hey"
// Note: We are printing the data part of each node for easy readability
console.log(list.head.data); // This should be "ho" since we have removed "hey"
console.log(list.selectNodeAt(1).data); // This will be "hum" since it is the first index after the head
All of the fancy schmancy ES6 linked list code I wrote, majorly standing on the shoulders of Cho Kim’s excellent tutorial, is available in this Gist.
Resources
- HackerRank video
- Data Structures With JavaScript: Singly-Linked List and Doubly-Linked List
- ES6 Classes
Whew!
I would bet around $500 that my following posts about my computer science studies with not be as involved as this initial one, but I do promise to keep writing. I’ll bet another $500 that, after all this, linked lists don’t show up at all in my interview…but you never know! This is good writing practice either way.
Next up in data structures: Linked Lists, Binary Trees, Tries, Stacks, Queues, Vectors/ArrayLists, and Hash Tables! At the time of this writing, I really don’t know what any of those are beyond general associations.
I also realize a linked list might work as a way to store this list of data structures I will be learning about because they are going to go in a particular order, probably.
Okay, time to go now. Stay tuned!
One response to “Day 1: Data Structures – Linked Lists”
[…] Linked Lists by Lara Schenck. This is an overview of a data structure that isn't native to any of the languages I spend the majority of my time in. Lara's series on computer science basics is a great primer for those of us without formal CS educations. […]