Trees and Binary Trees
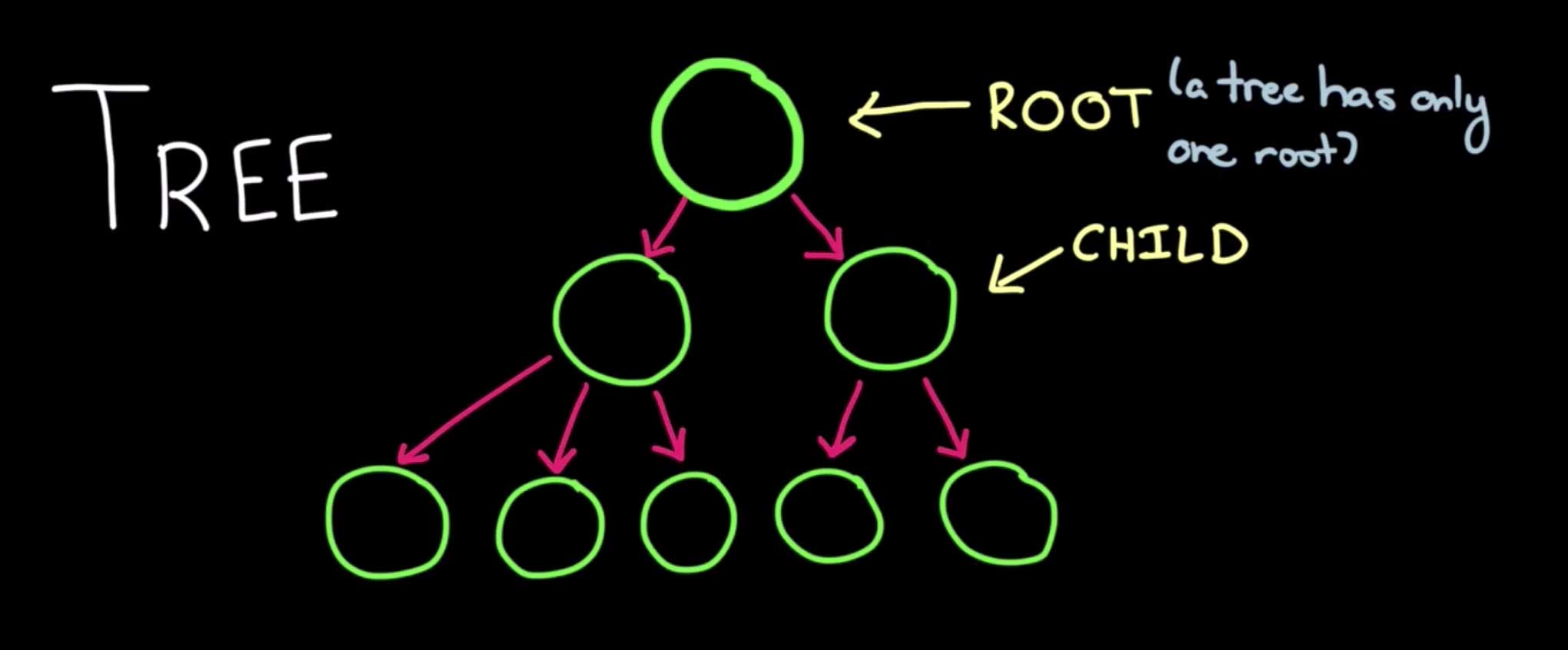
A tree data structure consists of nodes with a parent and children. Rather than a linear list like yesterday’s Linked List or your standard array, a tree looks like this:

Each parent node contains connections to its children. There is one “root” of the tree, or the top, great-great-great (or however many greats) grandparent node. Like in the above image, a parent node can have any number of children but, similar to humans having children, more than two can get out of hand.
A binary tree is a tree where each node has no more than two child nodes. If you’ve heard of binary code as in 1s and 0s, this is similar, except instead of a 1 and 0, the two choices are right and left.
A binary search tree is a binary tree that follows a specific ordering ruleset. That ruleset is:
- Left nodes are less than the root node
- All right nodes are greater than the root node
- In single parent with two siblings, the left node will be smaller than the parent and the right node will be larger than its parent.
So, I think you could say: Left node < Root node < Right node.
In the real world
There is one tree we web developers encounter on an hourly basis: the DOM! The DOM is a tree, the tree of all trees. Here’s another pretty sweet CodePen, this one by Mustafa Enes, that visualizes the DOM tree:
See the Pen DOM Tree Visualisation by Mustafa Enes (@pavlovsk) on CodePen.
If you edit this pen on CodePen, add some more markup to see where it lies within the tree.
You will notice that parent nodes in the DOM have more than two children, and that means that the DOM is not a binary tree or binary search tree (or BST as I’m seeing it abbreviated here and there). How about a real-life example of those?
There are several threads answering this question. To be quite honest, a lot of those answers confuse me greatly, but here’s are some hopefully plain language translations of those examples:
- 3D computer graphics by way of something called binary space partitioning. I think the gist here is that a scene is recursively (we’ll get to that later) divided into two, and the divisions are stored as nodes in a binary tree. The operation is complete when the nodes are divided such that only polygons that can be rendered in any order remain (whatever that means).
- Abstract syntax trees are used to break down functionality in programming languages. For example, the parent node might be a comparison operator and its two children are the variables being compared. ASTs are often used in compilers.
- Huffman Coding is a lossless compression technique. From my limited understaning, this has to do with assigning variable-length codes to input characters that also denote frequency. The most frequent character gets the smallest code and the least frequent the largest code, according to this description by Akshay Rajput.
- And, according to this Reddit thread, a spell check dictionary!
Inserting Nodes
The ordering in binary trees makes it much faster to search for a specific number or a place to insert a new node because you can chop off large sections of the tree based on these rules. For example, if your tree is like this:
10
/ \
5 20
/ \ / \
3 6 15 17
And you are looking for 2, you can immediate chop off the root and all the right branches because you know it will be on the left. Similarly, if you are looking for a place to insert an element into the tree, you can efficiently deduce where to do so. For example, if you are inserting 12 in the above tree, the program would make the following decisions:
- 12 > 10, so go to the right of 10
- Go down to 20. 12 < 20, so go to the left
- Arrive at 15. 12 < 15, so go to the left
- Found an empty spot, so staying there!
I found this FANTASTIC (yes, it is so great it deserves all caps) CodePen by Ron Gierlach that is an interactive representation of a binary search tree.
See the Pen Binary Tree by Ron Gierlach (@youfoundron) on CodePen.
How cool is that? I did a practice exercise with this where I selected a number and predicted where it would be inserted. The “Auto Balance” checkmark indicates the use of an algorithm to keep the branches at a similar length, which is a little harder to predict, but hopefully, you get the right idea. Ron has another rad Pen about linear vs. binary search which will probably make its way into another post. Thanks, Ron!
Traversing the Tree
There may be instances where we need to traverse the entire tree, maybe to print out each node’s value or to sum up all of the nodes. There are two ways to do this:
- Depth-First Search (DFS): Start at the root node and traverse the whole way down to the node at the very bottom with no children, a.k.a. a “leaf” node, then goes back to the root to make its way back down to the next leaf.
- Breadth-First Search (BFS): Systematically move through the tree level by level, hitting each node from left to right until there are none left.
This article has some nice gif visualizations of how those work. Which one you use depends on your situation.
Within DFS, there are also orders of traversal, whereas BFS is more linear, moving left to right. Given this simple tree and given the “current node” is the root, the orders of DFS would be:
B / \ A C
- Pre-order: Current node first, then left then right (B, A, C)
- In-order: Left, then current node, then right (A, B, C)
- Post-order: Left, right, then current node (A, C, B)
According to the Hacker Rank video, an in-order search is typically used in binary search trees, but for other purposes, I believe it just depends on your needs.
Let’s use DOM traversal as an example. You traverse the DOM every time you need to select an element. Every time you select something with jQuery’s $, you are traversing the DOM tree in order to find that element. Document.querySelector(), the vanilla JS equivalent of $, employs depth-first, pre-order traversal. Let’s say your markup is set up like so (using Pug notation for brevity):
html
body
article
header
h1.title
p.tagline
div.content
p
img
p
footer
p
If I want to find .tagline, the DFS search would go through the process like so:
- Enter the
htmlnode then intobodysince that is the only child bodyhas two children,articleandfooter. SincequerySelectoris pre-order search, look into the left child, orarticlefirst.- Similarly,
articlehas two children,headeranddiv.content. Look in the left one,headerfirst. - Now we are in
headerand it has two children,h1.titleandp.tagline. Look at the left one, orh1.titlefirst. h1.titlehas no children, so go to its right-hand siblingp.tagline.- Bingo! We have found
.tagline
If that node had not been .tagline, the program would have jumped back up to search through the closest right-hand node it had not yet investigated, in this case, div.content. Rinse and repeat!
In JavaScript
Like linked lists, the JavaScript representation of a tree data structure really just simulates an actual tree since there is no native data type to support trees. Once again, I will be following along with Cho Kim’s tutorial on CodeTuts, this time about Trees in JS.
Here is the skeleton of the code, including objects for the Node and Tree itself:
// In the linked list, I made the Node a class, but I opted for a function here since it doesn't require methods
function Node(data) {
this.data = data;
this.parent = null;
this.children = [];
}
class Tree {
constructor(data) {
let node = new Node(data);
this.root = node;
}
traverseDF(callback) {
// Function for depth-first traversal
}
traverseBF(callback) {
// Function for breadth-first traversal
}
contains(data, traversal) {
// Check if Node with `data` exists using one of the above traversals
}
add(child, parent) {
// Insert a new node and specify its parent and children
}
remove(child, parent) {
// Inverse of the above
}
}
// Create a tree
const tree = new Tree("Lara");
// Logs a tree with root "Lara" and no parents or children.
console.log(tree);
So, to be very honest, I have now lost patience with my tree studies and will be moving on to a new topic. There is SO MUCH to cover and, like I said in my linked lists post, not all of these accounts will be so invovled. I think there’s some good information in this one, though! If you would like to fill in the JavaScript, I encourage you to follow Cho Kim’s tutorial, as mentioned above.
Until next time, have fun with trees! Next up in data structures: Linked Lists, Binary Trees, Stacks, Queues, Tries, Vectors/ArrayLists, and Hash Tables.