The original premise of this post was to be an outline of the types of algorithms I mean when I say algorithms of CSS (which is becoming my schtick, in case you are new here!).
The thing is, there is serious prerequisite knowledge for a discussion about algorithms in our favorite declarative, domain-specific programming language: the domain! The browser! That translates to all kinds of Computer Science, so look forward to that, too.
So, before I get into writing about what I mean when I talk about algorithms in CSS, I want to make sure both you and I have a solid start for our mental model of a browser. There are many great resources out there already, and I recommend looking into those, too, but I also want to write this explanation in own words so that when I forget something in a few months (or weeks or days…), I have a resource with all of the information most pertinent to my brain for easy reference.
Before we begin, a small disclaimer that I will probably include at the top of every one of these posts:
The browser is a very complex and vast piece of software – there is no way I can cover everything. I will skip over large parts (if there is one you notice, leave a comment!). Also note that these posts might be a little rough around the edges. This is the Internet, however, so someone will catch any errors (please comment if you find one!), and I’m not too concerned about typs.
Okay…without further ado: Browser mechanics!!!!!! Browsers are really cool, and I hope to impart at least a tenth of my enthusiasm to you via exclamation marks here and there.
Step 1: Give me data; here is data
The browser, a.k.a. the client a.k.a. the front-end a.k.a. the user agent, receives a byte stream from a server as the response from an HTTP request. That looks kind of like this:

That request happens when you enter a URL – e.g. notlaura.com – into your URL bar.
notlaura.com is a domain name that points to a physical server* somewhere in the world – managed by my web host, Webfaction – that delivers the requested data back to your browser in the form of 8-bit bytes. Those bytes can ultimately be decoded into HTML, CSS, and JavaScript. Back-end languages might have been involved in creating that HTML, CSS, and JS, but that makes no difference to the browser.
* I’ll quickly define server, why not: A physical device or software program that exists solely to perform “services” for a client. In the case of websites, servers “serve” website files to the client when requested to do so. They also store data and perform computations when instructed to do so. The term server can refer to physical computer itself (they kind of look like stacks of futuristic pizza boxes) or server can refer to a set of programs that exist to return data in response to a request.
Step 2: Decode data from bytes to Unicode code points
Once the browser receives the byte stream, it must ultimately turn the bytes into tree data structures (which we will discuss more later). There are two trees we are concerned about here:
- A tree for HTML, a.k.a. our beloved DOM, or Document Object Model
- A tree for CSS, a.k.a the equally beloved (but less acknowledged) CSSOM, or CSS Object Model
Let’s look at how the heck this happens. Bytes do not just “turn into trees”.
Note: I am making it a goal for myself not to use the phrase “turn into” when talking about programming – it’s lazy and sounds like magic and this stuff is not magic. Join me in this undertaking! And if you find a place where I wrote “turn X into Y” please comment.
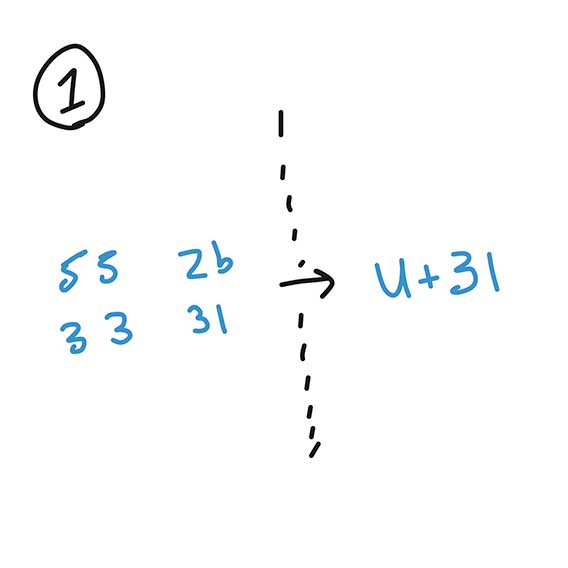
Oh yeah, what is a byte? A byte is eight bits, i.e. a group of eight 1’s and 0. They are often represented in hexidecimal format (yes, that is the very same as hex colors). Here is a hexidecimal byte sequence of a small CSS ruleset:
55 2b 36 38 20 55 2b 33 31 20 55 2b 32 30 20 55 2b 37 42 20 55 2b 32 30 20 55 2b 36 33 20 55 2b 36 46 20 55 2b 36 43 20 55 2b 36 46 20 55 2b 37 32 20 55 2b 33 41 20 55 2b 32 30 20 55 2b 37 30 20 55 2b 36 35 20 55 2b 36 31 20 55 2b 36 33 20 55 2b 36 38 20 55 2b 37 30 20 55 2b 37 35 20 55 2b 36 36 20 55 2b 36 36 20 55 2b 33 42 20 55 2b 32 30 20 55 2b 37 44
In order to make use of these bytes, standards require the browser, a.k.a. the user agent, to decode them into Unicode code points for parsing and tokenization (which will be the focus of part 2!). The server is responsible for sending a header that declares what encoding it used for the bytes so that the browser knows how to decode them into these Unicode code points.
Here is the above byte sequence decoded into Unicode code points:
U+68 U+31 U+20 U+7B U+20 U+63 U+6F U+6C U+6F U+72 U+3A U+20 U+70 U+65 U+61 U+63 U+68 U+70 U+75 U+66 U+66 U+3B U+20 U+7D
I, for one, would appreciate viewing this sequence decoded into English characters:
h1 { color: peachpuff; }
This string, when encoded as Unicode code points, would be the stream for the CSS parser.
I used this cool website called Cryptii for encoding and decoding bytes:

Note: There’s more I want to explore about this step – is there a difference between a byte sequence and a byte stream? Why the 00s in front of code points and 0xs in front of bytes in the Infra Standard? What is the Infra Standard? In the interest of moving this article forward, however, I’m going to pass on that for now.
A Computer Science takeaway
A big Computer Science takeaway concept: the decoded bytes – h1 { color: peachpuff; } – mean something to us, but they mean nothing to a computer all by themselves. The user agent must ultimately transform these characters into a structure from which it can glean instructions for rendering. That structure will be the forthcoming trees.
Also, I think the verb encode is used when converting data to a character encoding that is closer to binary, and decode when converting it closer to English characters. Those are some nice alternatives for “turn into”.
That’s it?
What happened so far in “Browser Mechanics In My Own Words”? Not much. We decoded hexidecimal bytes to Unicode code points. That makes up approximately 1/100,000 of what a browser does so this could be a long series, but that’s it for today!
I will leave you with this very high level and semi-accurate diagram of what the “turn into trees” process is going to look like (red dot means “we are here”):

The important part, right now, is to publish this damn blog post and get off the damn computer!!!! Sheesh.
Relevant links:
- Binary & Data – Khan Academy
- Bits, Bytes, Building with Binary – Vaidehi Joshi, BaseCS
- How do browsers work? – Lin Clark on Code Newbie
- HTML Syntax Specification, Editor’s Draft– w3c
- CSS Syntax Specification, Editor’s Draft – w3c